
Many teams can answer what a piece of code does, but far fewer can explain why it exists, what constraint shaped it, which tradeoff led to it, and whether that reasoning still holds, and that gap matters more now because we produce and change code at a pace where the loss of shared understanding is easy to miss until something important breaks.
Source code has no memory
We store source code, commits, pull requests, tickets, and documents, and over time the connections between them stop holding because they are not captured in a way that survives normal development, so branches disappear, tickets move between systems, pull requests capture moments of discussion, and months later the code remains while the reasoning has dissolved into fragments.
This is why a system can look healthy in the metrics we watch and still feel risky to change, since the tests pass, the linter is happy, the modules are named sensibly, and yet no one wants to touch the part that matters because the team no longer remembers which constraints were deliberate and which behaviors are accidental.
Margaret-Anne Storey describes this well in a recent paper and a related post, noting that we have many tools to measure code quality and very few ways to tell whether a team still understands the system or remembers why it was built that way, and that framing is useful because it gives a name to something many teams experience without quite being able to describe it.
It is not just technical debt
Technical debt still matters, since shortcuts accumulate interest and poor structure slows future work, though it only describes the state of the code and says much less about the state of understanding or the availability of the rationale that should guide change.
Storey's terms help here, where cognitive debt is the erosion of shared understanding and intent debt is the absence of explicit rationale, goals, and constraints, and the distinction matters because a codebase can be tidy and still be expensive to change when the team no longer shares a reliable model of how it works or what it is trying to preserve.
That is the failure mode I see most often, where messy code is visible and the deeper issue is that the theory of the system becomes unevenly distributed and the reasons behind earlier decisions were never captured in a form later developers can trust, so every change starts with reconstruction, and reconstruction is slow, error-prone, and rarely visible on a sprint board.
I see the same pattern in agentic development, where an agent can get stuck changing code back and forth, or move in a circle of revisions, because it does not understand why the code changed the last time. When the reason for a change is missing, the agent can still produce plausible edits, but it has no reliable way to tell whether it is preserving an intended constraint or undoing it by accident.
We try to fix it with process
Most teams have mechanisms that look like solutions, with tickets, commits, pull requests, and internal docs, and while all of these can help, they rarely preserve why a specific change exists in a durable way.
The link between these artifacts and the code is weak and optional, so tickets drift away, commit messages compress context, pull requests optimize for approval rather than rationale, and traceability turns into archaeology where the story can be reconstructed only with time and the right people.
That is not a workable model.
There is a real debate here
There is a real debate here, since some argue that documenting intent costs more than it gives back, especially when documentation becomes stale, and prefer to rely on code and tests while making changes based on present needs.
That criticism lands because much documentation is performative, with large documents that stop matching reality and create the appearance of control without helping decisions, and if that is the alternative then skepticism makes sense.
The useful middle ground is to capture rationale when it becomes concrete, since a short decision record, a task file with intent and constraints, or a merge-time summary tied to the change carries more value than large upfront documentation that quickly diverges.
This is starting to matter
This matters more now because AI-assisted development increases output faster than understanding can be built, since manual work forces cognitive effort that builds a model of the system while generated implementations still require that understanding and often leave the team with less of it than the output suggests.
The risk shifts from code quality alone to understanding and rationale, where teams can ship for a while and the cost shows up later during maintenance, onboarding, incidents, or audits.
This is especially visible in regulated environments, where you must explain what changed, who approved it, and why it was done, often for a specific change, and while teams can produce that answer, they do it by searching across systems because rationale is treated as residue instead of part of the change.
What is missing
What is missing is a property of the system itself, where a codebase should let you move from a line of code to the change that introduced it, to the unit of work that authorized it, and to the intent that made it reasonable at the time.
At a minimum, the chain looks like this:
code
<- commit
<- task
<- intent
Teams need a stable route from implementation back to reason, since without it every important question starts from scratch.
That applies to both teams and AI agents, because both need a stable route from implementation back to reason, from code change to intent.
A minimal model
The model can stay small, where each change carries a task identifier and a short statement of intent, branches and commits carry that identifier, tasks live close to the repository, and important decisions are captured in short ADR-style records, allowing tools to reconstruct the trace without relying on memory.
The format matters less than timing and discipline, since the reason needs to be captured while it is still available and in a form that survives time, which is why short decision records written at the moment of choice remain practical.
Shared understanding should be treated as a deliverable, since teams already allocate time for code and tests because those artifacts matter later, and rationale deserves the same treatment in a lighter form because future work depends on it in the same way.
In practice
In practice this needs to live close to the code, so when reading a file the question becomes whether the code can lead you back to the task, the intent, and the decision that shaped it, which separates traceability as paperwork from traceability as a working property.
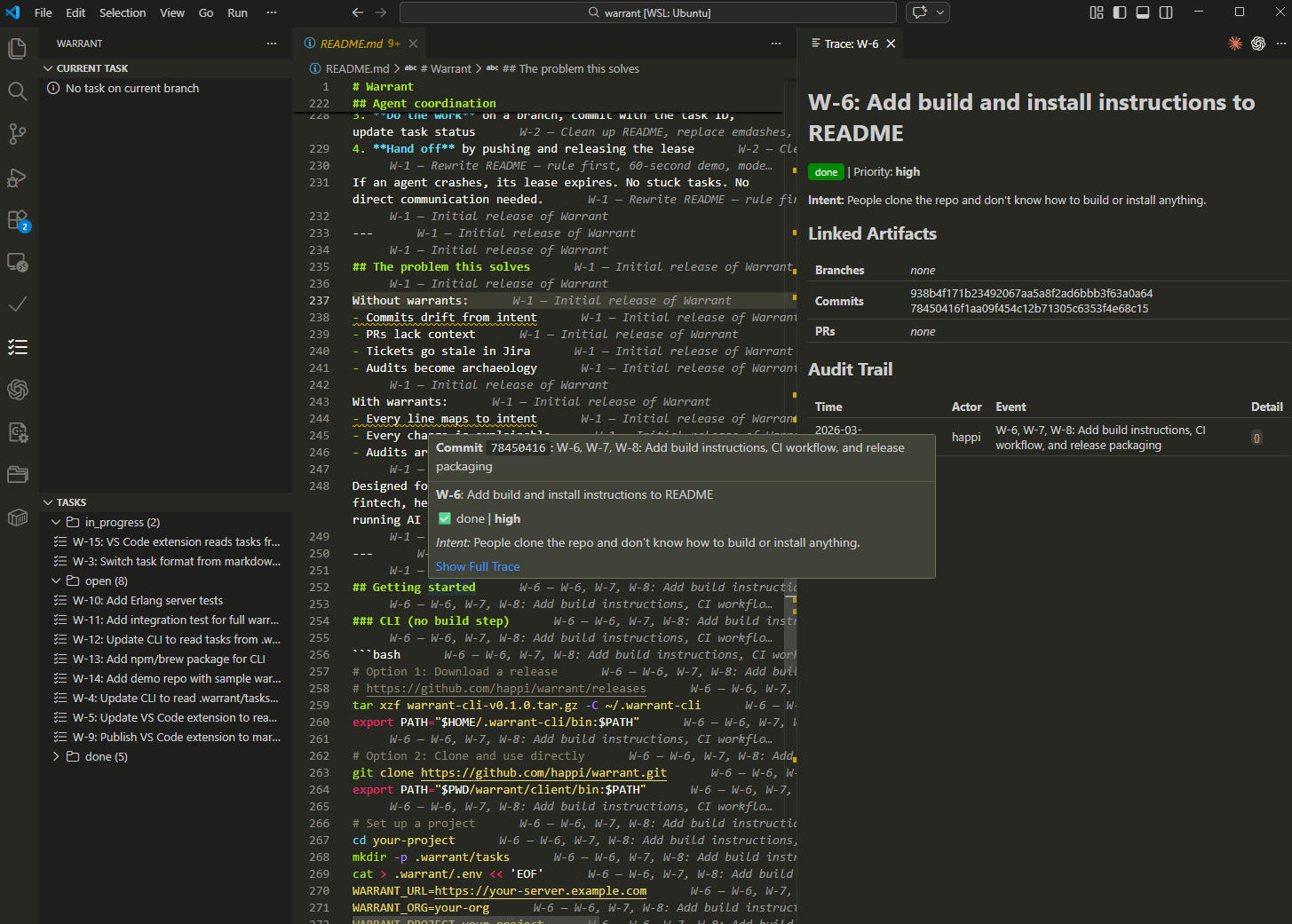
In Warrant, the VS Code extension follows simple conventions, reading task records from .warrant/tasks/, inferring the current task from the branch, and using git blame with task-linked commits to annotate lines, so the editor can show task context, intent, and history because the repository contains enough structured intent to reconstruct the story.
One important constraint
The repository needs to remain the source of truth, so tasks, intent, and decisions travel with the code and cloning the repository gives both the system and the context needed to understand it, while external systems can still add value without being the only place where rationale lives.
A separate concern: proof
Some environments need independent proof that a change followed an approved path, and in those cases a separate service can observe commits and merges and record an append-only account, allowing the repository to hold the work while the external system acts as a witness.
This avoids the trap where compliance systems own the work, since if the repository owns the work and the external service records events then you get evidence without moving the source of truth.
This is the space I have been working on with Warrant, where each change carries a small task record with an ID, intent, and decision, and when it reaches main the merge can be tied back to that task and optionally recorded in an append-only ledger.
That reduces the failure mode where rationale disappears after the pull request is closed. The tool itself is narrow and Git-native, and the point is the same as in the editor view above: preserve the why while the team still knows it.
What this changes
The practical effect is small and noticeable, since debugging starts from intent instead of guesswork, audits become closer to queries, onboarding improves because reasoning is visible, and AI-generated code becomes easier to place inside a controlled workflow because constraints and decisions are explicit.
More importantly, it means that when you come back to a piece of code and ask the question from the beginning, why does this exist, you are less likely to start from guesswork. Software systems need memory outside human recollection, since code stores behavior and Git stores change history while teams still need a durable way to store the reasons that connect one to the other. Without that, understanding erodes quietly and the system becomes harder to explain, evolve, and trust.
If you want to try it
If you want to try it, start with a few conventions where task IDs are in branches and commits, short intent records live next to the code, and lightweight ADRs capture decisions with lasting consequences, since consistency matters more than tooling and if the chain from code to change to intent exists reliably then the system starts to retain memory instead of depending on whoever still remembers the story.
If you're interested, you can find the current implementation in the Warrant repository.